

More Image(s)



Details
Start Small. Scale Only When Needed
Today’s AI servers consume and analyse data at much higher rates than traditional storage solutions an deliver. Resulting in low GPU utilisation and dramatically extending training times as well as decreasing productivity. PNY 3S-2400 has been developed from the ground up for AI workloads and NVIDIA DGX optimisation. Delivering ultra-low latency and tremendous bandwidth at a price which allows more investment to be made on GPU resource and less on expensive, slower storage.
Unlike most storage solutions where the initial investment dictates future growth and performance, often resulting in the need to overspend for potential future growth.
PNY’s NVmesh design can scale in stages to suit your project without any limitation. Just purchase the capacity and performance you need today and feel secure that as you scale, so can your capacity and performance..
Benefits of AI Optimised Storage
Real life deep learning projects show a massive 30% improvement in training times when compared to other solutions.Excellent performance with the standard storage synthetic benchmarks, with bandwidth, latency and IOPS, leaving others behind.
Cost and affordability are a key design focus. By removing the need for expensive storage controllers, costs are dramatically reduced, and more of your investment is spent on GPU and NVMe resource providing greater productivity and ROI.
With Scale-UP and Scale-OUT, both capacity and performance are not limited. Regardless of where you start, scaling is simple, fast and on demand.Providing a future proof solution and benefiting from the lowering trend of flash costs.
Increased Performance for AI workloads
NVMe over Fabric Low Latency Storage
Excelero delivers low-latency distributed block storage for web-scale applications.
NVMesh enables shared NVMe across any network and supports any local or distributed file system. The solution features an intelligent management layer that abstracts underlying hardware with CPU offload, creates logical volumes with redundancy, and provides centralised, intelligent management and monitoring.
Applications can enjoy the latency, throughput and IOPs of a local NVMe device with the convenience of centralised storage while avoiding proprietary hardware lock-in and reducing the overall storage TCO. NVMesh features a distributed block layer that allows unmodified applications to utilize pooled NVMe storage devices across a network at local speeds and latencies. Distributed NVMe storage resources are pooled with the ability to create arbitrary, dynamic block volumes that can be utilised by any host running the NVMesh block client.
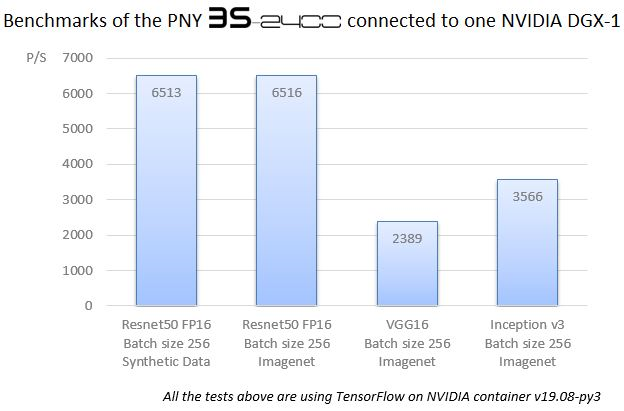
Leading Deep-Learning Performance Benchmarks
Resnet50 Benchmark (256) - 26 000 img/sec* (based on four DGX-1 and 2 node 15TB drive configuration)
Tests using TensorFlow on Nvidia container v19.08py3
| Flash Type | NVMe |
|---|---|
| Raw Capacity | Scalable |
| Usable Capacity | 360TB or 300TB in RAID 6 (for a 4U solution) |
| Effective Capacity | 720TB |
| Bandwidth | 46GBsec |
| Max. 4K IOPS | 8 million |
| Nominal Latency | <100 μS |
| Form Factor | 4U (2U for 32TB solution) - Scalable |
| Manufacturer | Excelero |
| Part No. | 3S-2400-NVME |
| End of Life? | No |