
AMD’s latest MI300 series is looking to challenge Nvidia’s market dominance and transform CPU-GPU integration. As the demand for high-performance computing continues to surge, the spotlight has predominantly focused on Nvidia's dominance in the GPU market. However, every year, AMD attempts to offer a viable alternative.
AMD’s MI300 series is so far confirmed to consist of two distinct products: the MI300X and the MI300A. The MI300X, it is a discrete ‘GPU-only’ version of the range, featuring 304 compute units distributed across eight chipsets and interconnected by Infinity Fabric mesh. The MI300A is classed as an ‘APU’, packing a combination of GPU and CPU capabilities into a single chip, offering the potential of enhanced performance and efficiency.

While Nvidia's A100 and H100 GPUs have garnered widespread recognition for their impressive performance across most AI workloads, the MI300X aims to directly compete by delivering comparable performance and advanced features. Nvidia’s H100 architecture includes a new streaming multiprocessor (SM), a new transformer engine, 80 billion transistors, 80GB of HBM3 memory capacity, a memory bandwidth of 3TB/sec, 50MB L2 cache architecture, and fourth generation NVLink.
This next-gen NVLink offers a 3x bandwidth increase on all-reduce operations and a 50% overall bandwidth increase over the A100. The SM features fourth-generation Tensor Cores which are up to 6x faster than their predecessors, as well as a 2x faster clock-for-clock performance per SM than the A100.
AMD claim the MI300X will allow you to run models with up to 80 billion parameters directly in-memory. The MI300X will feature 153 billion transistors, a HBM3 memory capacity of 192GB, and a memory bandwidth of 5.2 TB/s.

In the new AMD line-up, is the MI300A ‘APU’, which eliminates the need for a PCIe connection over the Printed Circuit Board (PCB) and DDR5 memory, leading to improved power efficiency and reduced latency. To achieve the integration of CPU and GPU in a single chip, the MI300A’s components are divided into chiplets, enabling manufacturers to achieve high yields and maintain comparatively low production costs. The chiplets are connected using interposers to eight 16GB stacks of third generation high bandwidth memory (HBM3) amounting to a total of 128GB, ensuring efficient communication between the components.
AMD's MI300A builds upon the foundations laid by its predecessors in the MI200 series, by introducing refinements. One standout feature is the MI300A’s utilisation of Zen 4 architecture for its 24 CPU cores, which brings enhanced performance and energy efficiency compared to the Zen 3 architecture found in the MI200 series. Furthermore, the GPU components will use the latest HPC and AI optimised architecture, CDNA 3 (Compute DNA generation 3). With 146 billion transistors. AMD cites up to an 8x advancement in performance of the MI300A over its predecessor, and a 5x increase in performance-per-watt, showcasing their commitment to optimising power efficiency in the latest MI300 series.
These substantial performance improvements claimed by AMD could be largely attributed to the potential introduction of dedicated INT4 pathways within their CUs. These INT4-specific pathways are expected to deliver a notable enhancement in AI inference tasks, where INT4 precision can commonly be employed. By incorporating these pathways, AMD could provide a significant boost to AI workloads, leveraging the inherent suitability of INT4 precision for such applications.
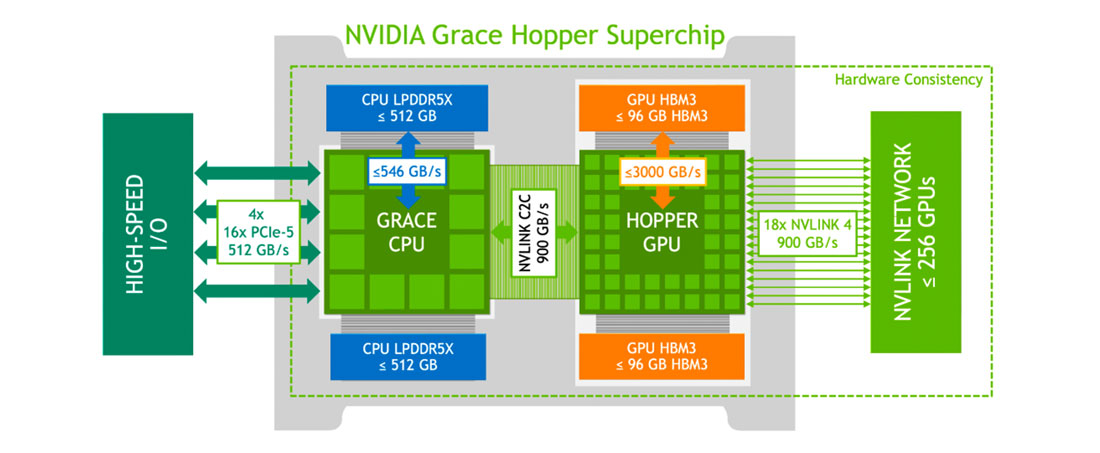
However, the MI300A will once again be facing fierce competition from Nvidia, with announcement of the new Grace Hopper CPU superchip at Nvidia’s GPU Technology Conference (GTC). Named in honour of the pioneering computer scientist. The Grace Hopper superchip is a powerful combination of the Grace CPU and the H100 tensor core GPU. This fusion is made possible by leveraging the Arm architecture in the CPU and the ultra-fast NVIDIA chip-to-chip interconnect, providing an impressive 900 GB/s coherent interface, a staggering 7x faster than PCIe Gen5. This presents the opportunity to deliver up to 30x higher aggregate bandwidth and up to 10x higher performance in terabyte-scale accelerated computing scenarios. NVLink-C2C technology allows for 1TB/s of LPDDR5X with error-correcting code (ECC) memory bandwidth and 144 Arm Neoverse V22 CPU cores with Scalable Vector Extensions (SVE2). However, the Grace Hopper chip will share two separate memory pools which has the potential to give the edge to the MI300A in certain scenarios.
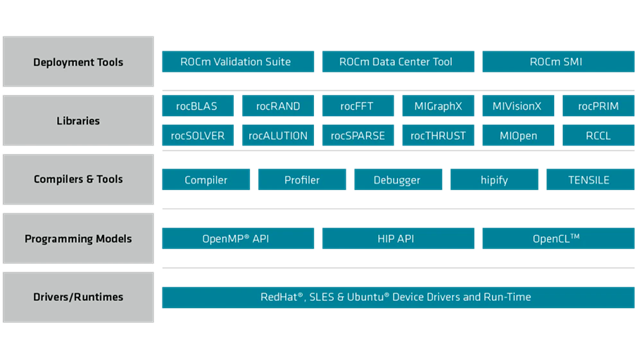
In order to compete with Nvidia in the AI market, AMD’s focus on its software stack will be of upmost importance. AMD has been developing its own proprietary software stack, at the centre of which lies the ROCm (Radeon Open Compute) platform, which serves as an ecosystem for GPU computing. ROCm provides developers with an assortment of open-source tools, libraries, and frameworks, allowing them to harness the potential of the MI300's GPU architecture. This includes ROCm's foundational components such as the ROCm Kernel Driver, which provides direct access to the GPU hardware, and the ROCr Runtime, which manages the execution of GPU compute tasks.
AMD's software stack also integrates key programming models such as HIP (Heterogeneous Computing Interface for Portability), OpenCL (Open Computing Language) and OpenMP (Open Multi-Processing). HIP is a C++ programming interface developed by AMD that provides a high-level abstraction layer and allows developers to write code that can be executed on both AMD GPUs and CPUs.
HIP is designed to be compatible with CUDA, NVIDIA's programming model, enabling developers to port CUDA applications to AMD GPUs using the HIP toolset. Much like CUDA, HIP provides a C++ dialect that supports various C++ constructs such as templates, classes, and lambdas. OpenCL, an open standard framework, provides a unified programming model and runtime environment for heterogeneous systems, encompassing GPUs, CPUs, and other processors. It allows developers to write code that can be executed on various hardware platforms, enabling efficient utilisation of resources. OpenMP, a widely adopted parallel programming model, enables developers to write code that can offload compute to GPUs in multi-node deployments using pragma target offload directives. It simplifies the process of parallelising applications by providing a set of directives and runtime libraries.
Furthermore, ROCm offers specialised libraries like MIOpen for deep learning primitives and MIVisionX for computer vision and inference tasks.
To further solidify its position in the data centre market, AMD is actively pursuing partnerships with industry leaders, aiming to establish support for the chip in their data centre offerings. At International Super Computing 2023, it was announced that the MI300A will power the two-exaflop El Capitan supercomputer at Lawrence Livermore National Labs (LLNL), which is expected to become the world's fastest supercomputer.
Despite all the steps taken by AMD to improve their market share, catching up with Nvidia will be a daunting task. Once a user commits to a given platform, it takes significant performance gains and reduced costs to entice a customer to change direction. Product availability will also be a key consideration.
To learn more...
BSI is a Dell Technologies Titanium Partner. Our Dell Technologies AI solutions can be viewed here and our AI inception programme here. Get in touch to discover how we could optimise your business with AI.
Our AMD and Intel server solutions can be viewed here and our AI servers here.
