
With the latest advancements in Deep Learning, the need for high performance computing and data analytics are rapidly growing as the complexity of modern Deep Learning models rockets. For large language models like BERT and GPT-3 [1], the number of parameters is approaching the trillions. The backbone of these colossal language models is a Machine Learning (ML) architecture called a Transformer [2].
The success of this model to Natural Language Processing has led to the adoption of such architectures in other areas of ML, such as computer vision. The resulting models (Vision/Swin Transformers) have been shown to outperform previous state-of-the-art vision models by a significant margin [3].
More recently, Transformer Models have even been adopted in the field of Reinforcement Learning (RL), where a problem-specific fitness function is used to reward/punish an agent as it adapts to a particular task set and environment. This demonstrates the huge potential of Transformer-based models as general-purpose models in a wide range of applications in ML and AI.

However, due to the sheer number of parameters needed in these models, it can take up to a month to train a single agent. This is prohibitively slow for most businesses. Luckily, high performance GPUs like the NVIDIA H100 Tensor Core GPU can significantly accelerate the training process. This brand-new H100 GPU is built with NVIDIA Hopper architecture, which is specifically designed to accommodate these next-generation AI workloads with massive compute power, fast memory and huge parallelism. The H100 is fabricated on TSMC’s 4N process – it consists of 80 billion transistors and 395 billion parameters, compared to 54.2 billion transistors on the A100. In addition, the H100 is equipped with 18,432 CUDA Cores – more than double the 8,192 CUDA Cores on the A100. The Hopper architecture also implements HBM3 High Bandwidth Memory with third generation NVLink, doubling the GPU-to-GPU direct bandwidth to 600 GB/s.
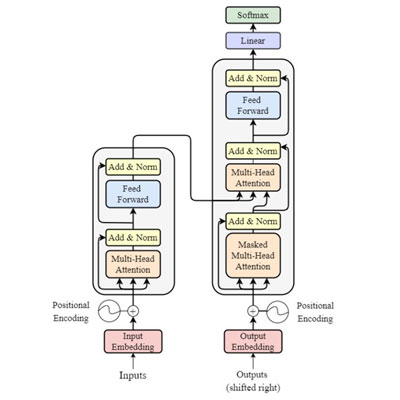
The core of Transformer models is the self-attention mechanism, which is built utilising scaled dot-product attention and multi-head attention modules. In the figure above, the attention modules are represented by the orange blocks and are stacked together with normalization layers, denoted by yellow blocks. Model inputs go through this architecture, and at each layer, hundreds of thousands of floating-point computations are completed. Most AI floating-point computation is done using 16-bit “half” precision (FP16), 32-bit “single” precision (FP 32) and, for specialized operations, 64-bit “double” precision (FP64).
However, for some computation layers, the same level of precision can be achieved using only 8-bit (FP8) precision computations, which halve the time to compute compared to FP16. The Transformer engine in the H100 GPU has special NVIDIA-tuned heuristics that dynamically choose between FP8 and FP16 calculations, while automatically handling the re-casting and scaling between these precisions in each layer.
In addition to this revolutionary Transformer engine, the NVIDIA Hopper architecture also advances its fourth-generation Tensor Cores, by tripling the floating-point operations per second compared to prior-generation architectures for all FP32, FP64, FP16 and INT8 precisions.
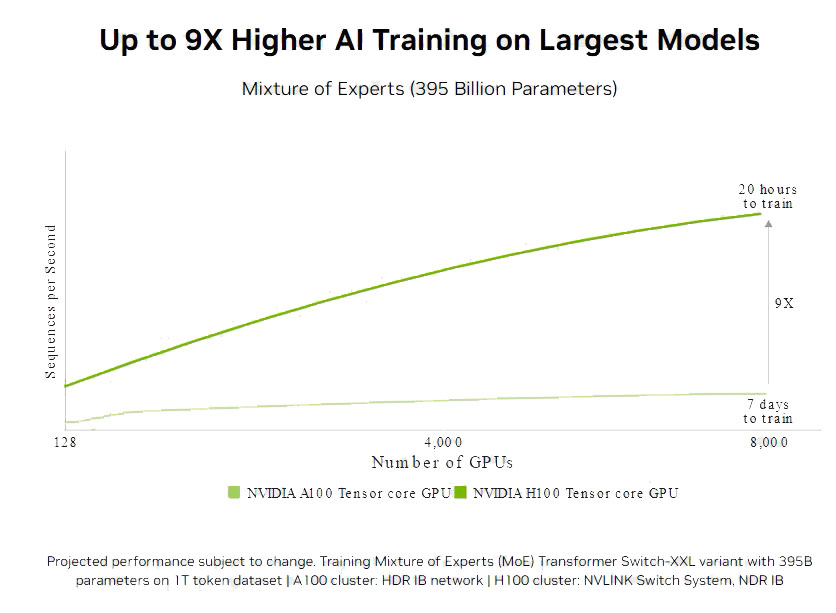
With these improvements, plus advanced Hopper software algorithms, the H100 speeds up AI performance by over 9x to allow for the training of large modern models within days instead of months. From a business perspective, the faster a model becomes operational, the earlier its return on investment begins.
The Transformer engine also accelerates model inference. Previously, INT8 was the standard precision for optimal inference performance. However, it requires trained networks be converted to INT8 as part of the optimization process. On the other hand, using models trained with FP8 allows developers to skip this conversion step altogether and perform inference operations with the same FP8 precision.
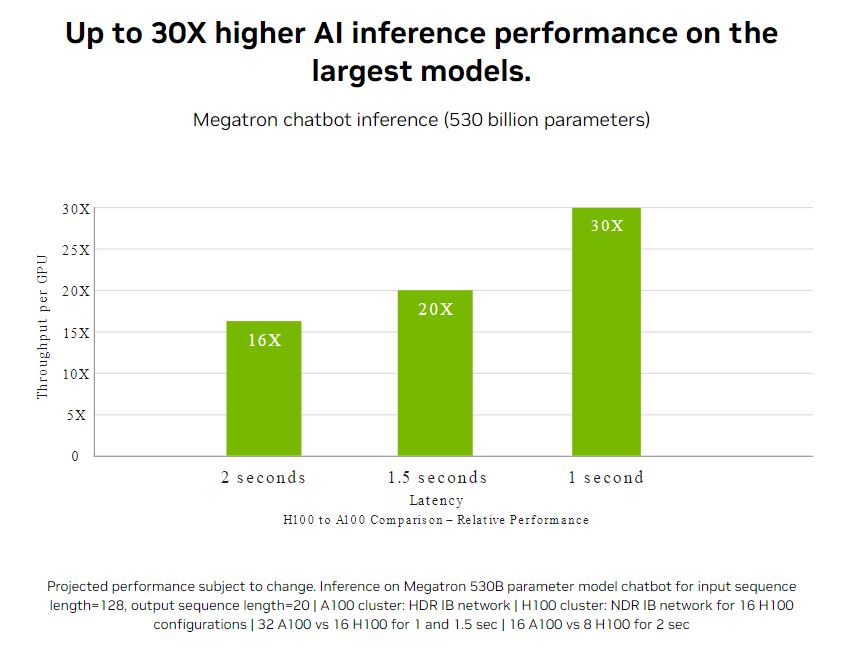
In addition, just like INT8-formatted models, deployments of FP8 models using Transformer engines can run in a much smaller memory footprint. On state-of-the-art large language models, NVIDIA H100 inference per-GPU throughput is up to 30x higher than previous generations, with a 1-second response latency, showcasing it as the optimal platform for AI deployments.
BSI is an NVIDIA Elite Solution Provider and has received the Nvidia AI Champion and NVIDIA Star Performer in Northern Europe awards.
The new DGX can be viewed and ordered here and the H100 PCIe card here.
To learn more...
Our AI solutions can be viewed here and our AI inception programme here.
Get in touch to discover how we could optimise your business with AI.
[1] T. B. Brown et al., “Language Models are Few-Shot Learners,” Adv Neural Inf Process Syst, vol. 2020-December, May 2020, doi: 10.48550/arxiv.2005.14165.
[2] A. Vaswani et al., “Attention Is All You Need,” Adv Neural Inf Process Syst, vol. 2017-December, pp. 5999–6009, Jun. 2017, doi: 10.48550/arxiv.1706.03762.
[3] Z. Liu et al., “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows,” Proceedings of the IEEE International Conference on Computer Vision, pp. 9992–10002, Mar. 2021, doi: 10.48550/arxiv.2103.14030.