
A distributed file system (DFS) is a type of file system that is designed to store, efficiently manage, and provide access to files across multiple nodes or servers in a computer network. Unlike traditional file systems that rely on a single centralised storage location, distributed file systems distribute data across multiple machines, enabling scalability, fault tolerance and improved performance.

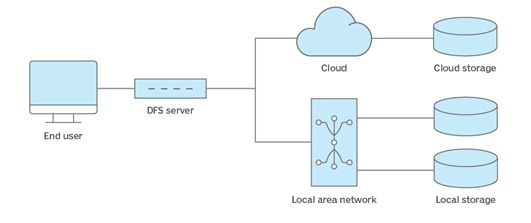 Figure 1: Distributed file system architecture.
Figure 1: Distributed file system architecture.
A brief history of DFS
The history of DFS dates back to the 1970s when the need to share files and resources across multiple computers emerged, prompting researchers to begin investigating solutions. One of the earliest distributed file systems was developed by Xerox at their Palo Alto Research Center and first demonstrated in 1972. The Xerox Network Systems allowed multiple machines to access files on remote servers through a network, laying the groundwork for future advancements in these systems.
Originating in 1984, Network File System (NFS) was developed by Sun Microsystems to enable file sharing across a network and quickly became one of the most influential distributed file systems. It operates on a client-server model, allowing multiple UNIX-based clients to access files stored on remote servers. NFS incorporates a communication protocol that permits clients to access files residing on a server and allows for heterogenous processes, which is important as the clients may be on different devices or use different operating systems.
Initially developed by IBM in 1983, Server Message Block (SMB) is a network file-sharing protocol first designed to provide multiple nodes running IBM’s OS/2 with access to files and printers on a Local Area Network (LAN). It provides a client-server model, where SMB clients can access shared files, directories, and resources on SMB servers. SMB supports features like file and printer sharing, authentication, access control, and file locking.
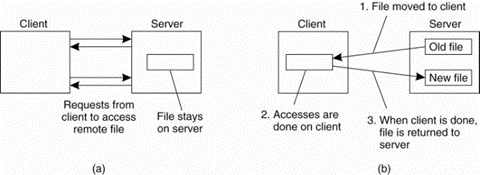 Figure 2: (a) Remote access model used by NFS. (b) Upload/Download model.
Figure 2: (a) Remote access model used by NFS. (b) Upload/Download model.
Microsoft later produced a version of SMB 1.0, named Common Internet File System (CIFS), which provided similar functionality to NFS but for Windows-based systems. CIFS extends the capabilities of SMB by adding support for internet protocols, such as TCP/IP, enabling file sharing across the World Wide Web. To ensure secure access, SMB authenticates users using either the New Technology LAN Manager (NTLM) or Kerberos protocol, enhancing the overall security of file-sharing operations.
DFS Architectures
DFS architectures can be broadly categorised into two main types: client-server and cluster-based. Each architecture offers distinct advantages and is suitable for different use cases and requirements.
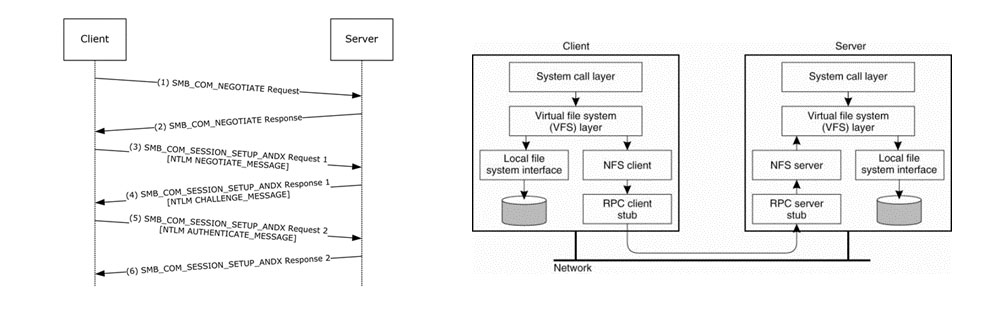 Figure 3: SMB session authentication sequence with NTLM messages & Figure 4: NFS client-server architecture.
Figure 3: SMB session authentication sequence with NTLM messages & Figure 4: NFS client-server architecture.
In a client-server architecture, the DFS consists of two primary components: the client and the server. The client, which is typically a user's machine or application, interacts with the server to access and manipulate files. The server is responsible for storing and managing the files, serving file requests from clients and controlling file system operations. This architecture offers benefits such as centralised administration, easier security management, and simpler data backup and recovery. However, they will likely face scalability challenges and performance bottlenecks when dealing with large-scale data sets or compute-intensive workloads. Client-server architectures are commonly used in long-established file systems like NFS and SMB/CIFS.
In a cluster-based DFS, files are distributed across the nodes in the cluster, providing scalability, fault tolerance, and improved performance. Clients can access files from any node in the cluster and the system transparently handles the retrieval and management of data across multiple nodes. A technique called file striping, where files are split into chunks and distributed across many storage containers, is employed to allow access to different parts of a file in parallel.
Cluster-based architectures offer several advantages. They enable horizontal scaling by adding more nodes to the cluster, allowing for increased storage capacity and improved performance as the workload grows. These architectures also provide high availability, as data redundancy and replication can be implemented across multiple nodes. Additionally, they offer better fault tolerance since the failure of one node does not result in the loss of data or service. However, this approach can result in an increased number of hardware failures.
Parallel file systems are a specialised type of DFS that distribute files across multiple servers and allow concurrent access to files by multiple tasks of a parallel application. Parallel file systems are designed to facilitate high-performance parallel processing of large-scale data sets and hence are commonly used in high-performance computing (HPC) environments. These systems employ techniques like data striping and parallel I/O to achieve extremely high throughput and low latency by optimising for scenarios where multiple nodes work together to process data simultaneously.
DFS architectures play a crucial role in managing and accessing files in distributed environments. Client-server architectures offer centralised control and administration, while cluster-based architectures provide scalability, fault tolerance, and high-performance capabilities. The choice of architecture typically depends on factors such as the specific use case, scalability requirements, performance needs, and the level of fault tolerance desired by organisations deploying distributed file systems.
Open Source DFS
There are many open-source distributed file systems, such as Ceph, BeeGFS and Lustre, which boast architectures expertly tailored for clustered environments. Each of these file systems is purposefully designed to excel in specific domains, catering to large-scale data sets, high-performance computing or resource-intensive workloads like AI and big data analytics.
Ceph is a highly flexible and scalable open-source DFS designed to address the challenges of managing large-scale data sets. It provides a unified storage solution for object, block, and file-based storage, making it suitable for a wide range of use cases. It uses a unique approach called Reliable Autonomic Distributed Object Store (RADOS), where data is automatically distributed and replicated across multiple storage nodes. Ceph is highly available and ensures data durability through techniques including replication, erasure coding, snapshots and clones. Its ability to scale horizontally and handle vast amounts of data has made it a popular choice for cloud service providers and organisations dealing with large-scale data storage needs.
BeeGFS, previously known as FhGFS, is a parallel DFS designed specifically for Linux HPC environments. It focuses on providing high throughput, low latency and scalability to meet the demanding requirements of HPC workloads. BeeGFS supports both small-scale deployments and large-scale clusters, making it suitable for a wide range of HPC applications, including AI, scientific research, and data-intensive computing. The hardware-independent POSIX file system is optimised for highly concurrent access to deliver optimal performance and robustness under any I/O load or pattern. BeeGFS uses a distributed architecture that separates metadata handling from data storage, allowing for improved performance and flexibility. This parallel design ensures that data can be read or written concurrently by multiple clients, reducing bottlenecks and maximising throughput.
Lustre is a versatile parallel DFS released in 2003 that is specifically designed for large-scale computing environments. Lustre was acquired by Sun Microsystems in 2007 and later by Oracle Corporation in 2010. Its architecture involves separating metadata and data storage, enabling it to efficiently handle huge volumes of data and metadata operations. It utilises a distributed namespace and parallel I/O capabilities to provide fast access to large datasets, making it ideal for applications with demanding I/O requirements, such as scientific simulations and big data analytics.
Conclusion
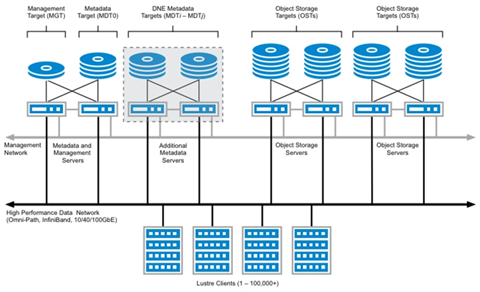 Figure 6: Lustre architecture.
Figure 6: Lustre architecture.
Distributed file systems play a critical role in effectively managing the expanding data volumes associated with AI workloads. By leveraging the power of distributed file systems, organisations can unlock the true potential of AI and pave the way for ground-breaking innovation. With the advent of increasingly powerful server hardware, the industry has recognised the inherent necessity of distributed file systems, favouring them over traditional file systems.
Historically, parallel file systems have been predominantly utilised for HPC workloads, but their complexity and the expertise required for implementation and maintenance have posed challenges to organisations. Collaborating with reputable data storage vendors, such as DELL Technologies, VAST, WEKA and DDN. Business Systems International can provide scalable solutions tailored to meet the diverse requirements of any organisation. With our comprehensive approach and cutting-edge technologies, we empower businesses to optimise their data storage infrastructure, achieve seamless scalability and effectively manage the complexities of modern datacentre environments.
To learn more...
BSI is a Dell Technologies Titanium Partner. Our Dell Technologies AI solutions can be viewed here and our AI inception programme here. Get in touch to discover how we could optimise your business with AI.
Our AMD and Intel server solutions can be viewed here and our AI servers here.
