
Tuning Hyper-parameters has been an expensive process in deep learning , especially for neural networks (NNs) with billions of parameters. Poorly chosen Hyper-parameters result in dissatisfactory performance and training instability. Many published baselines are hard to compare against one another due the varying degrees of HP tuning. These issues are exacerbated when training extremely large deep learning models, since state-of-the-art networks with billions of parameters become prohibitively expensive to tune.
This paper showed that by using the recently discovered Maximal Update Parametrization (µP), many optimal Hyper-parameters remain optimal even as model size changes. This means that we can parametrize the target model in µP, tune the Hyper-parameters indirectly on a smaller model, and zero-shot transfer them to the full-sized model, i.e., without directly tuning the latter at all.
The author of this paper called this paradigm µTransfer, and this can firstly dramatically reduce the cost of tuning by training a much smaller model, and secondly ensure the optimality of the Hyper-parameters by extensive tuning on the small model while directly tuning on the large model is intractable, i.e. too expensive.
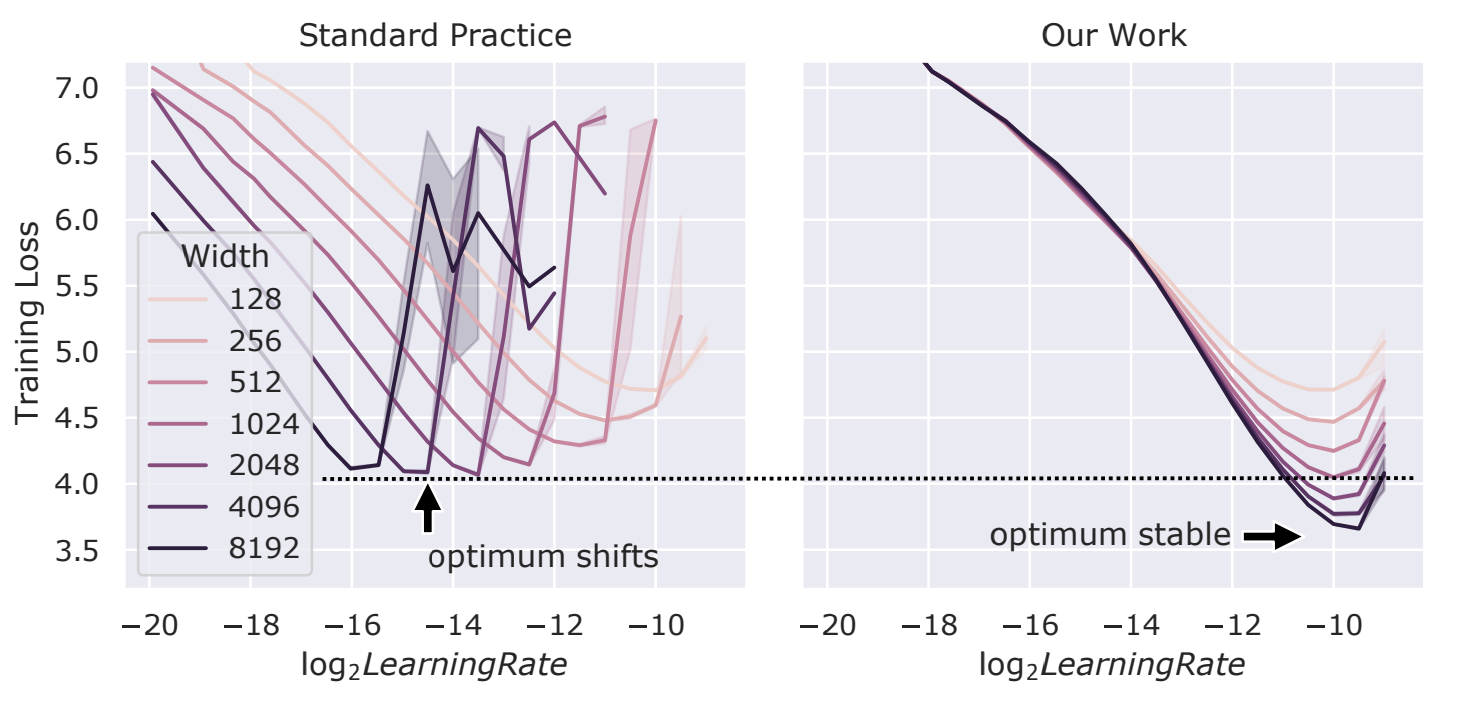
The authors verified µTransfer on Transformer and ResNet. For example, 1) by transferring pretraining HPs from a model of 13M parameters, this method outperform published numbers of BERT-large (350M parameters), with a total tuning cost equivalent to pretraining BERT-large once; 2) by transferring from 40M parameters, this method outperform published numbers of the 6.7B GPT-3 model, with tuning cost only 7% of total pretraining cost.
This article was provided by our AI researcher Bill Shao.

To learn more...
BSI is a Dell Technologies Titanium Partner. Our Dell Technologies AI solutions can be viewed here and our AI inception programme here.
Get in touch to discover how we could optimise your business with AI.